


Using ChatGPT in R Studio and Things to Know
R is used a lot in statistics and data analysis. So how can you use ChatGPT in R? This article will be of more interest to those who want to do statistical analysis and R lovers.
I have explained R Project and R studio installations in another article, if you haven't installed it yet, you can read the related article. You can also find my other articles about R & SEO on Zeo Blog.
Running ChatGPT in R & API Setup
To connect to ChatGPT via R, you first need to create an API at https://platform.openai.com/account/api-keys. Let's name and save the key and keep this code somewhere:
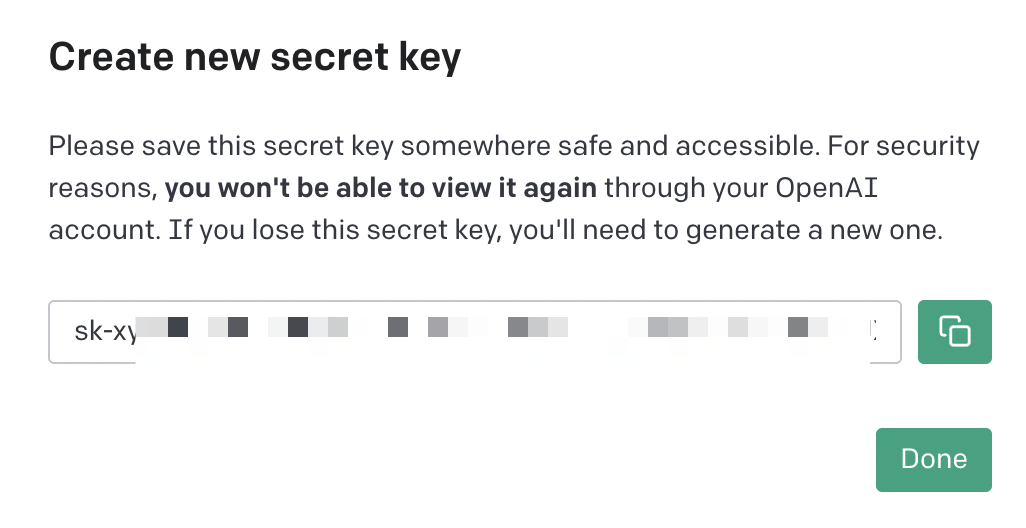
We go back to R, run our initial code and install the libraries:
library("TheOpenAIR")
We also add our API Key information into R:
library("TheOpenAIR")
openai_api_key("sk-apı_key")
The library needs to be installed as follows. You can also install this package below if ("dplyr") is not installed:

Sample Packages and Uses
Our package is installed and we now have a connection to OpenAI. All that remains is to enter the prompt we want:
chat("Write a 175 character meta description about how R Studio can be used for SEO")

After that, it will actually start to take shape depending on what we want from ChatGPT. For example, with "model" I can choose with gpt-3.5-turbo. You can also use GPT-4 if you want. With the "temperature" value, you can specify the value you want and try to get the best results:
chat("Write a short introductory text describing R Studio in 150 words",
model="gpt-3.5-turbo",
temperature=0.8)

You can specify the frequency with frequency_penalty: (Additional information)
chat("Write a short introductory text describing R Studio in 150 words",
model="gpt-3.5-turbo",
frequency_penalty=1,
temperature=0.8)

You can also use "count_tokens" to read the number of tokens in a URL, for example:
url <- "https://zeo.org/tr/kaynaklar/blog/chatgpt-anahtar-kelime-analizi-ve-google-sheets-otomasyonu"
count_tokens(url)

You can elaborate on what can be done differently depending on your projects or work. I am giving these examples to summarize the situation. For example, you can get help here for FAQ fields:

I want to create a sample data.frame and visualize it. I am writing a clear prompt:
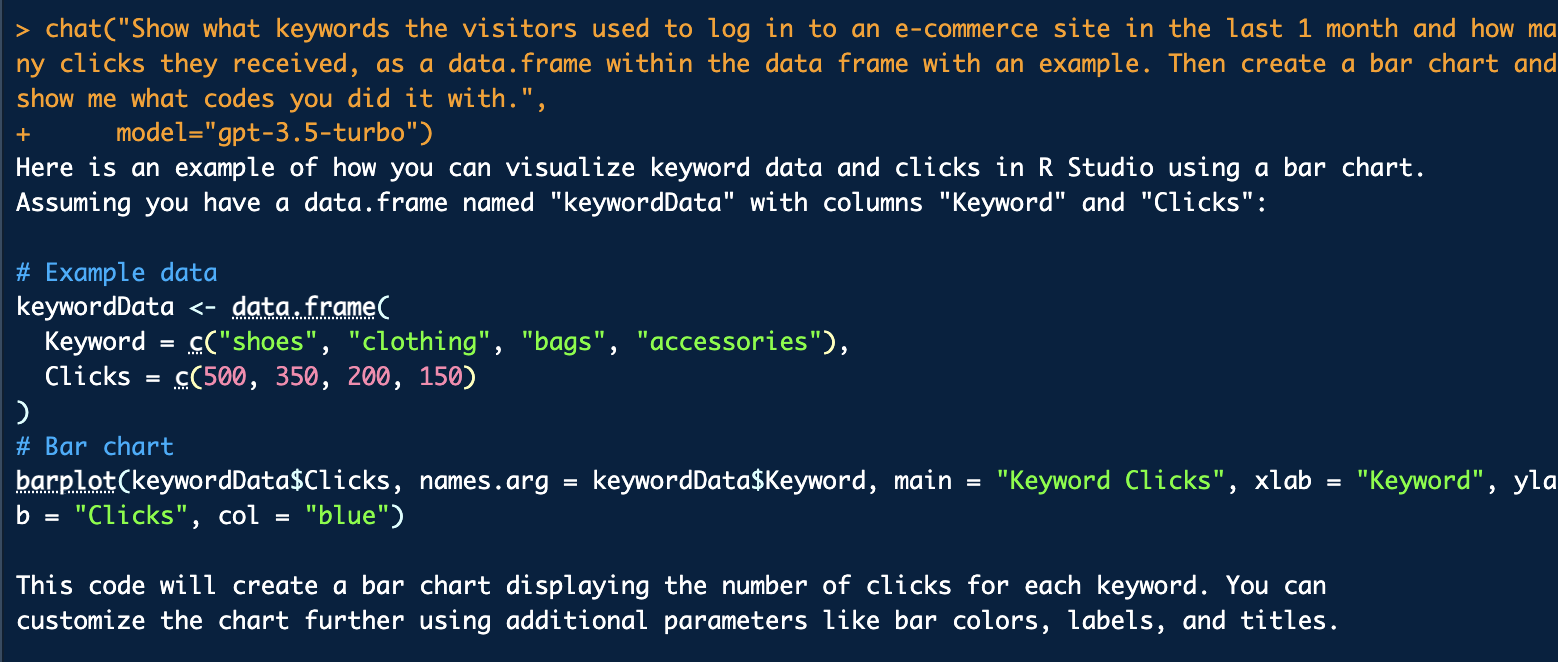
chat("Show what keywords the visitors used to log in to an e-commerce site in the last 1 month and how many clicks they received, as a data.frame within the data frame with an example. Then create a bar chart and show me what codes you did it with.",
model="gpt-3.5-turbo")
The output directly tells me how to do this step by step:
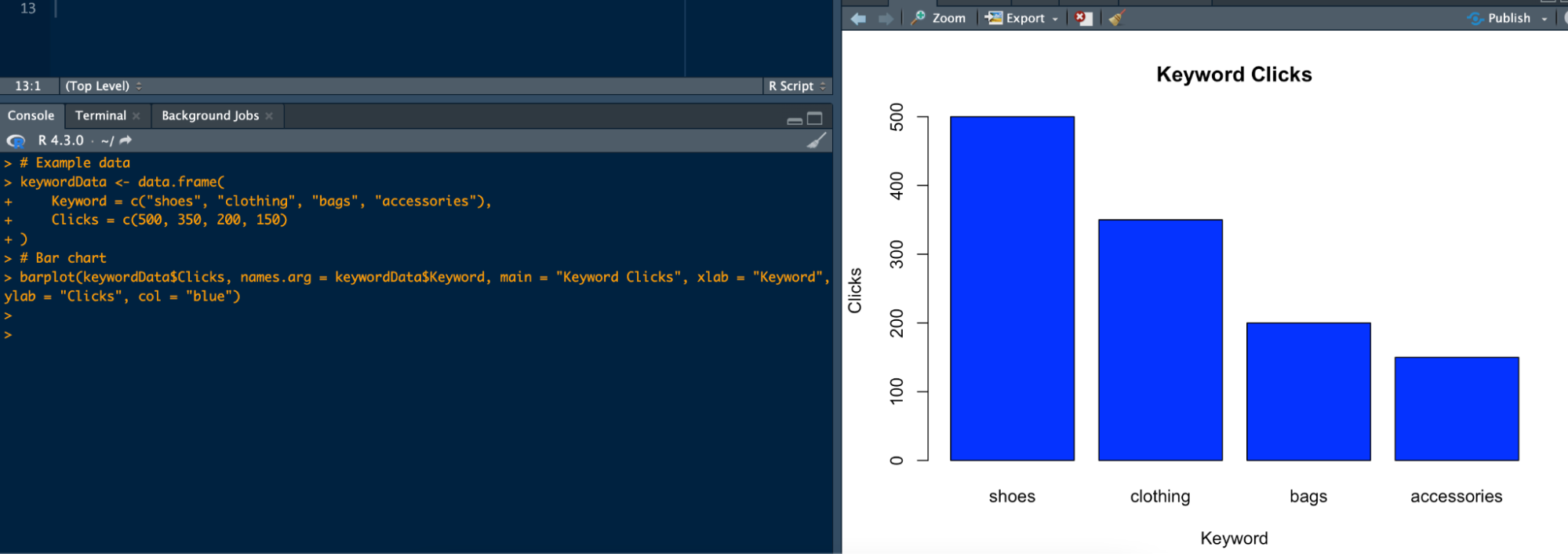
As a result, I created the graph I wanted. I've explained how to import a .csv or .txt file into R and even how to scan URLs in other articles, so I won't go into those details:
You can also turn the answer you receive from ChatGPT into a vector in one line. You can then ask this vector all the questions you want or perform statistical analysis. The View command is also a command you can use to view this data set you have already created: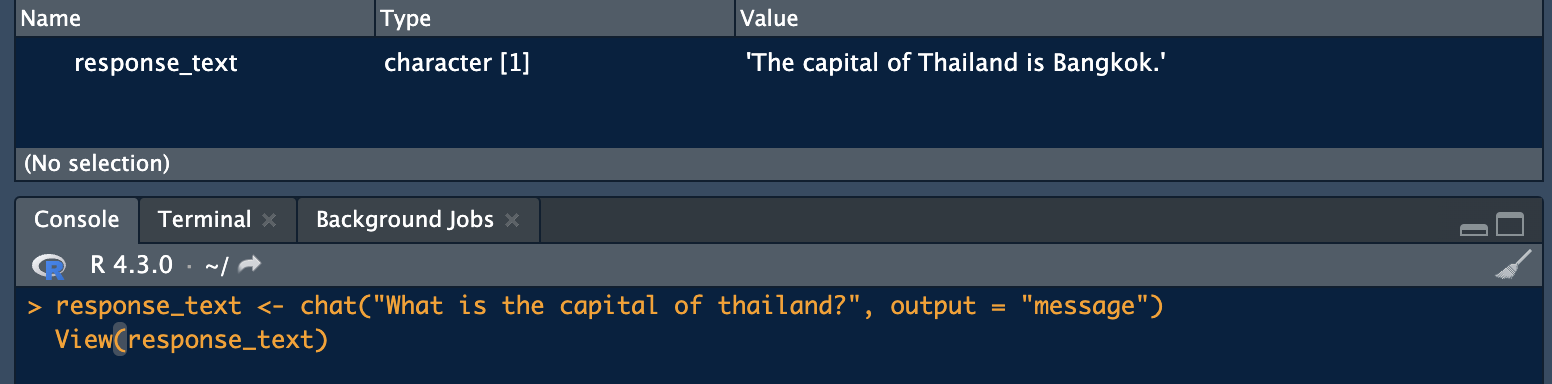
response_text <- chat("What is the capital of thailand?", output = "message")
View(response_text)
For example, you can divide this answer by dots to get a list of sentences.

sentences <- strsplit(response_text, "\\.")[[1]]
print(sentences)
Again, I want him to write an article and create a word cloud based on the sentences in this article:
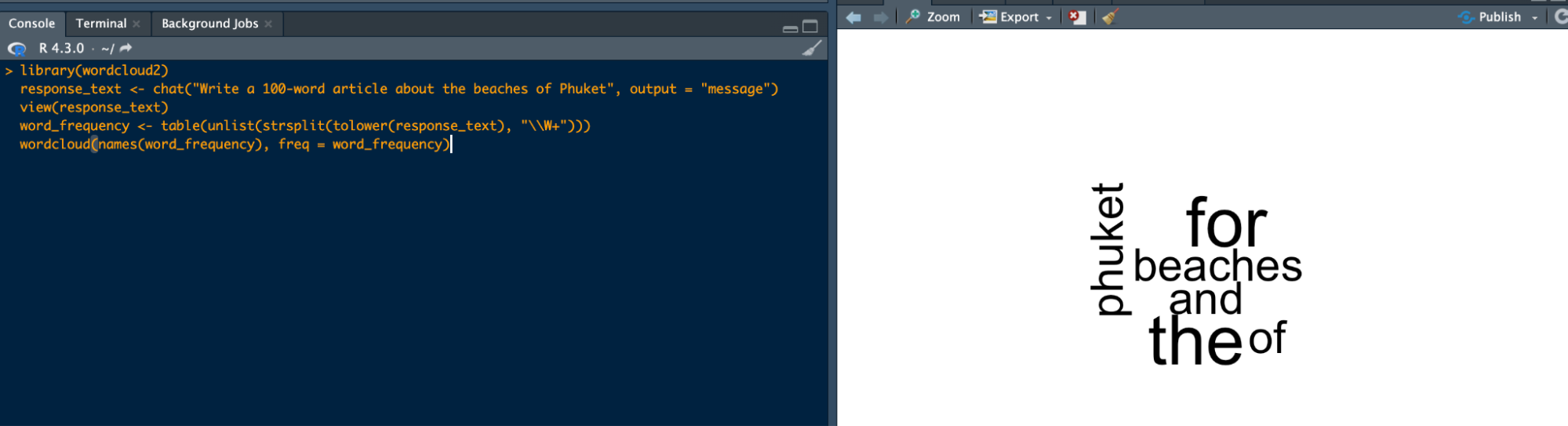
library(wordcloud2)
response_text <- chat("Write a 100-word article about the beaches of Phuket", output = "message")
view(response_text)
word_frequency <- table(unlist(strsplit(tolower(response_text), "\\W+")))
wordcloud(names(word_frequency), freq = word_frequency)
You can find subjective judgments in an article as follows. You can specify what comes after "grep", I wrote it as an example:

subjective_judgements <- grep("famous|wonderful|beautiful", tolower(response_text), value = TRUE)
subjective_judgements_number <- length(subjective_judgements)
print(subjective_judgements)
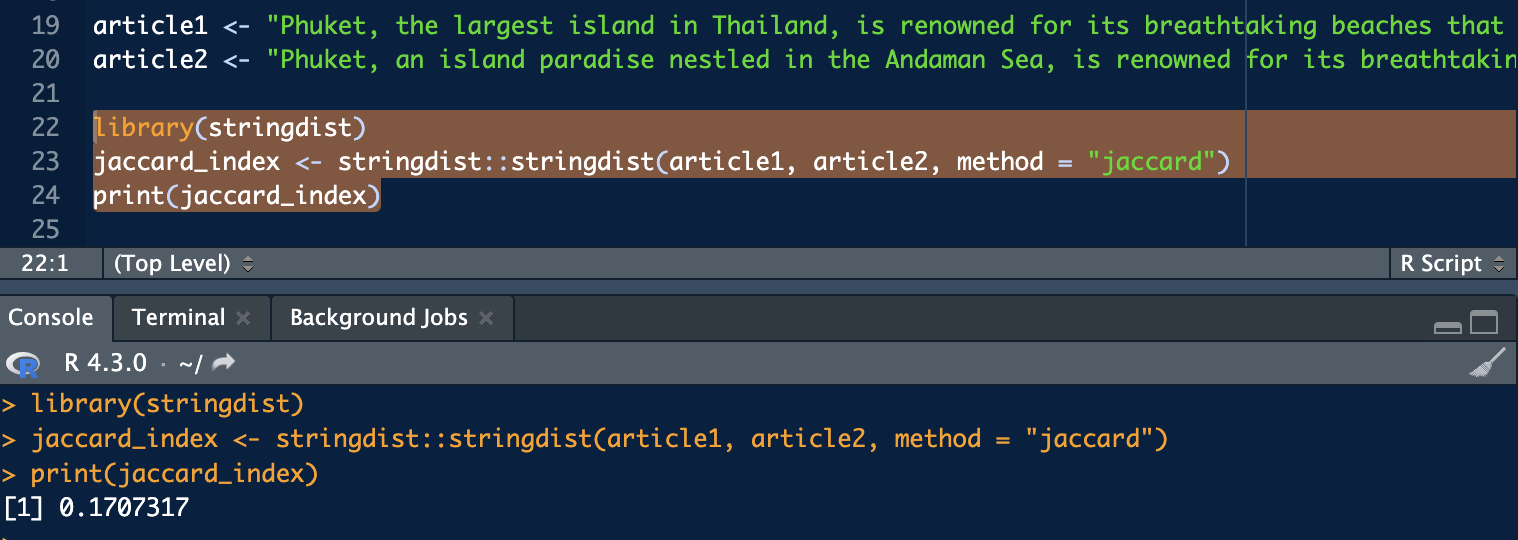
CI asked ChatGPT to create 2 articles on the same topic and then I wanted to analyze if there were any common words between the texts using jaccard similarity. It showed me that there were no common texts:
library(stringdist)
jaccard_index <- stringdist::stringdist(article1, article2, method = "jaccard")
print(jaccard_index)
A Jaccard similarity scale of 0 indicates that there are no words in common between the two texts or that all words are different. In this case, the Jaccard similarity can be interpreted as 0 and there is no similarity between the two texts:
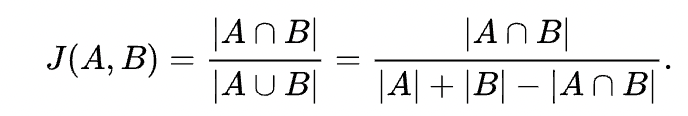
I wish everyone who has read this far a day with lots of statistics and making their work with AI as easy as possible.



















